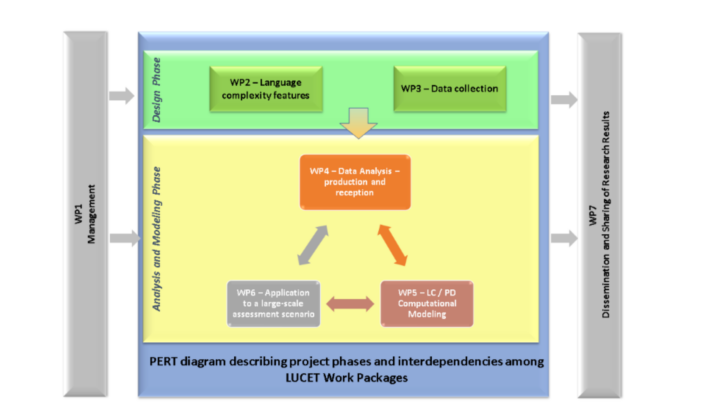
WP1 – Project management
T1.1 Administrative and financial project coordination
T1.2 Scientific and technical coordination
T1.3 Quality assessment, ethics compliance, data and risk management
WP2 – Language complexity features
T2.1 Sampling and monitoring of complexity features for each linguistic sub-domain (lexicon, morphology and syntax), literature review on Linguistic Complexity (LC) features and measures for each linguistic sub-domain, selection and tracking of features contributing to LC
T2.2 Measuring language complexity – starting from the literature review and based on existing corpora and resources, a set of LC features will be piloted via computational modeling in order to define a final set of measures to be used in later stages
WP3 – Data collection
T3.1 Target Populations
- identification of target populations (students with typical and atypical development, monolingual and multilingual speakers) and sampling criteria
T3.2 Resource collection
- survey and collection of relevant resources (e.g. corpora of educational materials labeled with grade 13) to be used for i) detecting, tracking and weighting LC features, and ii) building Linguistic Complexity (LC)/Processing Difficulty (PD) models collection and evaluation of existing corpora of linguistic productions by the target populations
T3.3 Collection of production and comprehension data
- collection and evaluation of existing testing materials
- construction of new comprehension and elicitation tests and tasks
- collection of linguistic production by the target populations
WP4 – Data analysis
T4.1 Describing complexity features in productions of typically and atypically developing students
T4.2 Describing complexity features in productions of monolingual and multilingual students
T4.3 LC features in comprehension (product-oriented perspective: response accuracy) – analysis of impact of LC features in determining PD in typical and atypical language development and use, and in monolingual and multilingual speakers
T4.4 LC features in comprehension (process-oriented perspective: reaction times and eye-tracking) – analysis of impact of LC features in determining PD in typical and atypical language development and use, and in monolingual and multilingual speakers
WP5 – Computational models of LC/PD
T5.1 Linguistic preprocessing of collected corpora
- specialization of the linguistic annotation tools
- multi-level linguistic annotation of collected corpora
T5.2 Feature extraction from linguistically annotated corpora – extraction and quantification of LC features from multi-level annotated texts
T5.3 Computational modeling of processing difficulty – for each target population, definition and construction of PD models, both global and sub-domain specific
WP6 – Applications to a large-scale assessment scenario
T6.1 Defining the applicative scenario
T6.2 Applying the resulting LC/PD models to stimulus-passages from the INVALSI item bank
T6.3 Specification of the psychometric models
T6.4 Feedback and adaptation of the models
WP7 – Dissemination and Sharing of Research Results
T7.1 Project website – establish the project website to be updated at least every six months
T7.2 Dissemination of Results – disseminate research results by
- distributing a newsletter on project results to potential stakeholders,
- organizing initiatives for discussion, feedback and exploitation purposes, targeting the scientific community and potential stakeholders, and
- submitting papers to scientific conferences and journals