There are two major varieties of syntactic annotation: a phrase structure and a dependency representation. In general, a phrase structure representation may be found more suitable for languages with rather fixed word order patterns and clear constituency structures. Dependency representations, in contrast, may be found more adequate for languages which allow greater freedom of word order and in which linearisation is controlled more by pragmatic than by syntactic factors. This is the case in Finnish (and the Slavonic languages, some of which, such as Czech and Polish, may be expected to have increasing association with the EU in the future). Less obviously, some Romance languages (Italian and Spanish) may also benefit from a dependency representation. However, this does not mean that languages such as English should be annotated using a phrase structure representation or, vice versa, that for languages with greater freedom of word order, dependency should be used. Indeed, dependency structures have been successfully applied to English using the English Constraint Grammar (Karlsson et. al. 1995) and the Slot Grammar Parser (McCord 1990).
Since the approach to syntactic annotation is to a large extent influenced by the language to be annotated, our guidelines do not give any preference either to a phrase structure annotation or to a dependency annotation. The phrase structure annotation, however, is in certain ways the more demanding of the two, which is why this report covers phrase structure in more detail. This should not be construed, however, as expressing a preference for phrase structure annotation.
The two possibilities mentioned here, Dependency and simple Phrase Structure grammar models, are certainly not the only options available to annotate a corpus. Other approaches, such as LFG and complex phrase structure grammar models such as GPSG and HPS, may be equally successful. However, the reason why only phrase structure and dependency grammars are covered here is that by now these two models have a certain tradition in corpus annotation; and they have been used to annotate corpora both manually and automatically. Though it is true that HPSG parsers exist, there are no corpora, as far as we know, annotated using a HPSG formalism, nor are there any existing HPSG parsers robust enough and of sufficiently wide coverage to serve as a basis for corpus annotation.
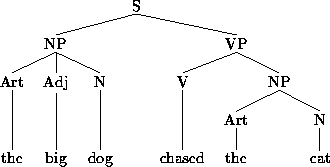
We will propose notations for both approaches. A typical Phrase Structure tree is shown in 69:
| (69) |
|
| (70) | [NP The big dog NP] [VP chased [NP the cat NP] VP] |
| (71) | [PP in [NP the heat [PP of [NP the night]]]] |
| (72) | [in [the heat [of [the night NP] PP] PP] NP] |
| (73) | [PP in [NP the heat [PP of [NP the night NP] PP] NP] PP] |
Dependency trees can be represented with arrows pointing from the head to the dependents or from the dependents to the heads . Of these two conventions, we recommend the use of the latter, as in 74:
| (74) |
|
| (75) |
|
We note further that an alternative dependency representation has been suggested. Since dependency trees are directed a-cyclic graphs they can be represented by bracketed expressions, just as constituency trees. The governing term is placed first, and is enclosed in brackets, including all dependent terms which are themselves included in brackets. Example 74 can then be represented as in 76 (with part of speech categories added):
| (76) | [V chased [N dog [det the] [Adj big]] [N cat [Det the]]] |
| (77) |
|
| (78) | [PRED [SUBJ [DET the] [ATTR big] dog] chased [DIROBJ [DET the] cat]] |
As with phrase structure representations, less fine-grained analyses are possible too, as in 79 (see bracketing single word constituents):
| (79) | [PRED [SUBJ the big dog] chased [DIROBJ the cat]] |