This layer of information comprises head-dependent relations between words, e.g. adjectives and the nouns they modify. It is often assumed that the showing of dependency relations between words (dependency syntax) is an alternative to labelled bracketing (phrase structure syntax) as a way of indicating syntactic constituency relations, and indeed the two methods of indicating syntactic structure have overlapping functions. But they also convey different kinds of information (see below), and since both may be (independently or simultaneously) marked in a text, there is no difficulty in treating them as separate layers of annotation for the present purpose.
Dependency relations are traditionally indicated with arrows; these point from a head to a dependent, as in 6, although they may point in the opposite direction, showing the relation of a dependent to the head, as in 7. Note that there are some differences of opinion as to which words are heads and which words dependents. For example, within the NP, the noun may be regarded as the head of the determiner, or vice versa.
| (6) |
|
| (7) |
|
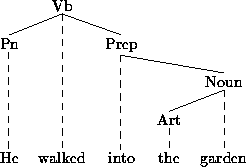
In many cases, dependency relations can also be represented by a tree
structure, as in 8![]() .
Heads are shown as nodes at the upper
ends of branches (slanted lines) and dependents are shown at the lower
end of branches. Thus, walked is analysed as the head of both
he and
into; into of garden; and garden of
the.
.
Heads are shown as nodes at the upper
ends of branches (slanted lines) and dependents are shown at the lower
end of branches. Thus, walked is analysed as the head of both
he and
into; into of garden; and garden of
the.
| (8) |
|
As far as we know, the ENGCG parser is the only system of corpus
annotation that uses a partial dependency syntax, and can be used as an
exemplar![]() . An example of ENGCG output
is given in table 6;
the output
was obtained from LingSoft's e-mail
parser. Instead of the arrows of the traditional dependency
representation, the symbols < and > are used to indicate
dependents; < means that the word's head precedes, > that it
follows. The link is established in the syntactic function
label. For example, @DN> indicates that an is a
determiner (D) whose head is a noun (N) that follows. If the
head is not the next noun but the second following one, the
notation @DN2> is used. The symbols @+FMAINV and @-FMAINV
represent a finite verb and a non-finite verb respectively.
. An example of ENGCG output
is given in table 6;
the output
was obtained from LingSoft's e-mail
parser. Instead of the arrows of the traditional dependency
representation, the symbols < and > are used to indicate
dependents; < means that the word's head precedes, > that it
follows. The link is established in the syntactic function
label. For example, @DN> indicates that an is a
determiner (D) whose head is a noun (N) that follows. If the
head is not the next noun but the second following one, the
notation @DN2> is used. The symbols @+FMAINV and @-FMAINV
represent a finite verb and a non-finite verb respectively.
Although there are a number of resemblances between phrase structure and dependency trees, it is not always easy or possible to convert one to the other. In the classical phrase structure representation, as in 5, heads are not marked at all, so a mechanical conversion will require stipulation of what the head of each dependent is in order to be able to create the dependency chain. Conversely, since in classical dependency syntax constituency plays no role (constituents as such are not indicated), the boundaries of a constituent have to be reconstructed from a subtree of a dependency tree. Thus, in 8, the part of the dependency tree dominated by Prep defines a prepositional phrase. However, dependencies may also be discontinuous, not mapping on to a context-free phrase structure tree.
Since phrase structure trees and dependency trees convey overlapping types of information, it is unusual for a syntactic annotation scheme to include both. We regard them in this report as alternative methods of indicating structural relations between parts of a sentence.