This section examines approaches to multiword recognition and extraction and automatic term recognition (ATR). We will examine linguistic and statistical approaches to ATR. There are no purely statistical approaches to ATR. Statistical approaches come rather from the areas of collocation extraction and IR. The second and third sections examine collocation extraction and the sub-area of IR that relates to ATR, indexing, and how they influence multiword ATR.
Researchers on multiword ATR seem to agree that multiword terms are mainly noun phrases, but their opinions differ on the type of noun phrases they actually extract. In the overview that follows, most systems rely on syntactic criteria and do not use any morphological processes. An exception is Damerau's work [Dam93].
Justeson and Katz [Jus95] work on noun phrases, mostly
noun compounds, including compound adjectives and verbs albeit in very
small proportions. They use the following regular expression for the
extraction of noun phrases
| ((Adj|Noun)+|((Adj|Noun)*(Noun-Prep)?)(Adj|Noun)*)Noun | (5.1) |
Daille et al. [Dai94] also concentrate on noun phrases. Term formation patterns for base Multi-Word Unit (base-MWU), consist mainly of 2 elements (nouns, adjectives, verbs or adverbs). The patterns for English are:
Bourigault [Bou92] also deals with noun phrases mainly consisting of adjectives and nouns that can contain prepositions, usually de and à, and hardly any conjugated verbs. He argues that terminological units obey specific rules of syntactic formation. His system does not extract only terms.
In [Dag94a], noun phrases that are extracted consist of one or more nouns that do not belong to a stoplist. A stop list is also used by [Dam93]. Damerau uses morphological analysis for inflectional normalisation.
The most common statistics used, is frequency of occurrence of the potential multiword term ([Jus95,Dag94a,Dai94,Eng94,Per91]).
[Dai94] investigate more statistical scores, since the frequency of occurrence would not retrieve infrequent terms. Several scores have been tested, among which are the one itemized below where:
| (w1,w2) is the pair of words, a is the frequency of occurrence of both w1 and w2 |
| b is the frequency of occurrence of w1 only |
| c is the frequency of occurrence of w2 only, and |
| d is the frequency of occurrence of pairs not containing neither w1, nor w2. |
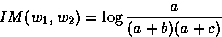 |
(5.2) |
 coefficient, introduced by [Gal91] for the
concordance of parallel texts
coefficient, introduced by [Gal91] for the
concordance of parallel texts
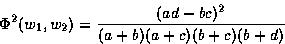 |
(5.3) |
[VanE94] uses statistics for finding the pairs of terms from the
source and target language. The translations of the terms of the
source language are ranked according to the following measure
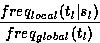 |
(5.4) |
[Dam93] uses the difference of two association ratios, one for a corpus
consisting of various subdomains and one for a subcorpus of a specific
domain.
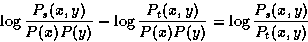 |
(5.5) |
The probabilities P are estimated by the frequencies normalised by the size of the corpus, t stands for the total corpus and s for the subject sub-corpus.
Multi-word recognition and compounding can benefit from the use of semantic relations between head and its modifier(s). It is nevertheless, an enormous problem to identify the types of semantic relationships (which have to be inferred) occurring. The possible interpretations between constituents may be constrained if we are working in a sublanguage. [Fin80,Fin86].
For term interpretation semantic relations, taxonomic information is of relevance. For term extraction collocational information has been used. Recently, there is a move for term sense disambiguation which uses techniques close to word clustering (see section 5.1.2, especially taxonomy-based semantic similarity). Automatic term sense disambiguation can be based on the identification of relevant contextual information.(see section 5.2.3 Frantzi & Ananiadou). General information about semantic roles from the corpus with domain-specific information about semantic categories from a specialised thesaurus can be combined. [May98]. Term sense disambiguation differs from word sense disambiguation in that the majority of technical terms are multiword. The ambiguity of terms is generally not caused by different senses of the individual components of the term, but by different senses of the term as a whole. The different meanings of the term may be linked to different domains, but they may equally be present within a specific domain.
The second stage, parsing, extracts substrings from the noun phrases extracted from the previous stage, as additional likely terminological units. These are extracted according their position within the maximum length noun phrases.
[Bou92] argues for the non-necessity of complete syntactical analysis, but the use of a surface grammatical one.
TERMIGHT [Dag94b] has been designed as a tool for the extraction of terms for human and machine translation. It consists of a monolingual and a bilingual part.
As a tool, it seems to be more concerned with issues like speed and how easy it is for users. The text is tagged and terms are extracted according to a regular expression and a stop-list.
Termight has a high recall, partly expected since there is no threshold on the frequency of occurrence of the candidate terms, but partly not, since a lot of terms are expected to contain adjectives, which are not treated at the current version of Termight.
As for the bilingual part, TERMIGHT identified the candidate translations of a term, based on word alignment. The candidate translations for each source term are displayed, sorted according to their frequency as translations of the source term.
Daille et al. work on English and French corpora [Dai94], each consisting of 200,000 words of the field of telecommunications. Only 2-word terms are considered. They are extracted according to morpho-sysntactic criteria, allowing variations on terms. All the variations add up as a list to each term. To the candidate terms extracted, a statistical score (likelihood ratio) is to be applied as an additional filter.
The approach gives preference on recall over precision, unless a high improvement on precision can be gained with a low loss on recall. This is actually the case where the preposition is excluded from the regular expression.
The following tables are created: a table that holds the global frequencies of the target language terms and source language term, a table that holds the local frequencies of the target language terms. The candidate translation terms are ranked according to , where tl stands for translation terms, and sl for source terms. The score should be greater to 1 for the target term to be extracted as a translation to the source term. The assumption is that the translated term is more likely to be more frequent in the target text segments ligned to the source text segments that contain the source term, than in the entire target text.
TERMINO adopts a morphosyntatic approach. The morphological analyser finds the stemming and does the part-of-speech tagging. The syntactic part consists of the parser and the synapsy detector. The parser resolves the remaining lexical ambiguity and gives the syntactic structure. A synapsy is a ``polylexical unit of syntactic origin forming the nucleous of a noun phrase'' ([Dav90]:145). It comprises a noun head that may be preceded by an adjectival phrase or/and may be followed by an adjectival phrase or prepositional phrase complement.
The synapsy detector consists of two parts. The first part, the synapsy builder, is activated each time a noun phrase is encounted by the parser. At this stage the head of the noun phrase is assigned a syntactic structure. The second part, the sysnapsy comparator, applies empirical criteria to filter out some of the noise. This criteria include frequency and category, as well as stop lists for the adjectival modifiers and the position of head.
The verb of the previous example is carrying information within the medical domain. There are cases where a particular environment that carries such information can be found in more than one domains, like the form ``is called'' of the verb ``to call'', that is often involved in definitions of terms in various domains. Our claim is that context, since it carries such information should be involved in the procedure for the extraction of terms. We incorporate context information to the approach of Frantzi & Ananiadou [Fra96a] for the extraction of multiword terms in a fully automatic way5.1. The corpus used is tagged. From the tagged corpus, the n-grams using the following regular expression are extracted (Noun|Adjective)+Noun The choice of the regular expression affects the precision and recall of the Our choice is a compromise between the two. For these n-grams, C-value, a statistical measure for the extraction of terms, based on the frequency of occurrence, and ``sensitive'' to nested terms5.2 is evaluated [Fra96a].
According to [Fra96b], the C-value integrates the parameter of the length of the n-gram. The length was used as a parameter when C-value was applied for the extraction of collocations [Fra96b]. Its weight ie weakened as shown in 5.6, where:
| a is the examined n-gram, |
| |a| the length, in terms of number of words, of a, |
| f(a) the frequency of a in the corpus, |
| bi the candidate extracted terms that contain a, |
| c(a) the number of those candidate terms. |
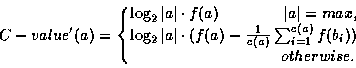 |
(5.6) |
¿From that list, the higher ranked terms are considered for the context evaluation. By context, we mean the verbs, adjectives, nouns, that appear with the candidate term. We attach a weight to those verbs, adjectives, nouns. Three parameters are considered for the evaluation of these weights: the number of candidate terms the word (verb, adjective, noun) appeared with, its frequency as a context word, and its total frequency in the corpus. The above are combined as shown in 5.7, where:
| w is the noun/verb/adjective to be assigned a weight, |
| n the total number of candidate terms considered, |
| t(w) the number of candidate terms the word w appears with, |
| ft(w) w's total frequency appearing with candidate terms, |
| f(w) w's total frequency in the corpus. |
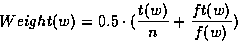 |
(5.7) |
 |
(5.8) |
| a is the examined n-gram, |
| , the previously calculated , |
| wei(a), the context weight for a, |
| N, the size of the corpus in terms of number of words. |
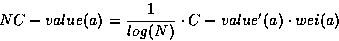 |
(5.9) |
To recognize and extract Multi-word lexeme (MWL) we use the finite state technology ([Kar93,Kar92] which provides an efficient and fast implementation environment.
Some MWLs always occur in exactly the same form and can therefore be easily recognised by their lexical pattern. This is the case for expressions like footloose and fancy free or out of the blue. However, most MWLs allow different types of variation and modification5.3. To be able to recognize such MWLs in a text, occurrences deviating from the standard or base form of the MWL have to be identified, e.g. different inflections, word orderings and modified uses. For example, in casser sa pipe (to kick the bucket), no plural is possible for the noun, the verb cannot be replaced by its near-synonym briser, nor can the phrase be passivised without losing its idiomatic meaning. Yet, the verb itself can be inflected.
Simple string matching methods are too weak to identify MWLs because most of them are not completely fixed. Besides, the variations they can undergo are, in most cases, lexicographically not well defined. A dictionary entry usually provides the reader with one form of the expression - not necessarily the base or canonical form -, giving no details about allowed variations, except sometimes lexical variants. This type of missing information can be stated with local grammar rules which have more general expressiveness than traditional descriptions.
Local grammar rules describe restrictions of MWLs compared to general rules by implicitly stating allowed variations of the MWL compared to the default case of a completely fixed MWL. In the default case, all restrictions apply, i.e. no variation at all is allowed, and the MWL is represented by the surface form of all lexical components in a fixed order. Violations to standard grammatical rules, e.g. missing constituents or agreement violations, need not be stated explicitly, though if necessary they can be expressed to distinguish the idiomatic from a literal use of the lexical pattern. To write the local grammar rules we use the two-level formalism IDAREX (IDioms As Regular EXpressions) developed as part of the FSC finite state compiler at Rank Xerox Research Centre 5.4. The local grammar rules we write are restricted to cover at most sentence length patterns. They are formulated as generally as possible, allowing for overgeneration. Although more specific and restrictive rules could be written, this is unnecessary because we assume that there is no ill-formed input. Indeed, it does not matter if the rules allow more variations than the ones that will actually appear in texts as long as idiomatic and literal uses can be distinguished. For instance, as long as we are not concerned with the semantic representation of MWLs, the local grammar rule for the French expression peser dans la balance accepts semantically correct phrases such as peser lourd dans la balance or peser énormément dans la balance, but also the semantically ill-formed peser *ardemment dans la balance. More generally, local grammar rules are also useful for syntactic parsing, e.g. by describing complex adverbials such as dates Le lundi 21 aout au matin5.5 or any other expressions that do not follow the general syntax. In many cases the syntactic parser would just fail because it would not be able to analyse properly the multi-word expression embedded in a larger phrase. For instance in German, the general syntax states that a determiner should precede any count noun. This rule is infringed in the MWL von Haus aus (originally).
Regarding the techniques we use, the two-level morphological approach based on finite state technology together with the IDAREX formalism, have the advantage of providing us with a compact representation. As we saw, we can define general variables, such as ``any adverb'' (ADV) or more specific morphological variables, such as ``only verbs in the third person singular'' (Vsg3). This relieves the lexicographer from the burden of explicitly listing all the possible forms. Functional variables provide a means to formulate generalizations about patterns that can occur for a whole class of MWLs. Besides, the two levels enable us to express facts either with the surface form or with the lexical form. Therefore, when we want to say that a given form is fixed, we just have to use the surface form without bothering with all the features on the lexical side.
In this technology, operations like addition, intersection, substraction and composition are allowed on the networks generated from regular expressions. Although we have not used this possibility in our work on local grammars yet, it is very powerful. For instance, if we are concerned about the semantics of a MWL and want to be more restrictive with the rules, we can build new regular expressions and substract the resulting networks from the one we already built. Such additional regular expressions would, for example, express facts about the compatibility of semantic classes of adjectives and nouns.
De reparatie- en afstelprocedures zijn bedoeld ter ondersteuning voor zowel de volledig gediplomeerde monteur als de monteur met minder ervaring. (The repair and adjustment procedures are meant to aid the fitter who has completed his degree work as well as the less experienced fitter.)After part-of-speech tagging, the noun phrase transducers will recognize and isolate the following noun phrases: reparatie-en afstelprocedures, ondersteuning, volledig gediplomeerde monteur, monteur and ervaring. The current noun phrase mark-up was designed basically for terminology extraction from technical manuals. It covers relatively simple noun phrase detection, i.e. some constructions such as relative clauses are not included.
Because one can easily add a new regular expression to handle more constructions, more elaborate patterns including verbs can be extracted. The same automatic means have been used to extract collocations from corpora, in particular, support verbs for nominalizations. In English, an example of proper support verb choice is one makes a declaration and not one does a declaration. Make is said to support the nominalization declaration which carries the semantic weight of the phrase. We used NLP suites followed by syntactic pattern matching slightly more complicated than the noun phrase extractors of the previous section, in order to extract verbal categorization patterns for around 100 nominalizations of communication verbs in English and French [Gre96].
Similar approaches are used to identify more sepcific items such as: dates, proper names. They use a combination of regular expressions as described above and specific lexical ressources including, for instance, semantic information.