Word clustering is a technique for partitioning sets of words into subsets of semantically similar words and is increasingly becoming a major technique used in a number of NLP tasks ranging from word sense or structural disambiguation to information retrieval and filtering.
In the literature, two main different types of similarity have been used which can be characterised as follows:
Both types of similarity, computed through different methods, are used in the framework of a wide range of NLP applications.
The methods and techniques for clustering words that we will consider here will be parted according to the kind of similary they take into account:
Typically, semantic similarity is computed either on the basis of taxonomical relationships such as hyperonymy and synonymy or through distributional evidence. The former approach presupposes prior availability of independent hierarchically structured sources of lexico-semantic information such as WordNet [Mil90a]. With the latter approach, the semantic similarity between two words W1 and W2 is computed on the basis of the extent to which their typical contexts of use overlap. The notion of taxonomy-based semantic similarity crucially hinges on words' membership of more general semantic classes. By contrast, distributionally-based semantic similarity rests on the assumption that words entering into the same syntagmatic relation with other words can be seen as semantically similar, although in this case the similarity may be grounded on some covert properties orthogonal to their general semantic superclass.
In this section, methods which assess semantic similarity with respect to hierarchically structured lexical resources will be discussed.
In Rada et al. [Rad89] and Lee et al. [Lee93], the assessment of semantic similarity is done with respect to hyperonymy (IS-A) links. Under this approach, semantic similarity is evaluated in terms of the distance between the nodes corresponding to the items being compared in a taxonomy: the shorter the path from one node to another, the more similar they are. Given multiple paths, the shortest path is taken as involving a stronger similarity.
Yet, several problems are widely acknowledged with this approach. First, other link types than hyperonymy can usefully be exploited to establish semantic similarity. For instance, Nagao [Nag92] uses both hyperonymy and synonymy links to compute semantic similarity where higher similarity score is associated with synonymy; with hyperonymy, similarity is calculated along the same lines as Rada et al. [Rad89], i.e. on the basis of the length of the path connecting the compared words. Yet other scholars have attempted to widen the range of relationships on the basis of which semantic similarity can be computed; see, among others, [Nir93b] who also use morphological information and antonyms.
Another problem usually addressed with the path-length similarity method is concerned with the underlying assumption that links in a taxonomy represent uniform distances, which is not always the case. In real taxonomies, it has been noted that the ``distance'' covered by individual taxonomic links is variable, due to the fact that, for instance, certain sub-taxonomies are much denser than others. To overcome the problem of varying link distances, alternative ways to evaluate semantic similarity in a taxonomy have been put forward.
Agirre and Rigau [Agi96] propose a semantic similarity measure which, besides the length of the path, is sensitive to
Resnik [Res95] defines a taxonomic similarity measure which dispenses with the path length approach and is based on the notion of information content. Under his view, semantic similarity between two words is represented by the entropy value of the most informative concept subsuming the two in a semantic taxonomy, the WordNet lexical database (see §3.4.2) in the case at hand. For example, (all senses of) the nouns clerk and salesperson in WordNet are connected to the first sense of the nouns employee, worker, person so as to indicate that clerk and salesperson are a kind of employee which is a kind of worker which in turn is a kind of person. In this case, the semantic similarity between the words clerk and salesperson would correspond to the entropy value of employee which is the most informative (i.e. most specific) concept shared by the two words.
The information content (or entropy) of a concept c -- which in WordNet corresponds to a set of such as fire_v_4, dismiss_v_4, terminate_v_4, sack_v_2 -- is formally defined as . The probability of a concept c is obtained for each choice of text corpus or corpora collection K by dividing the frequency of c in K by the total number of words Wobserved in K which have the same part of speech p as the word senses in c :
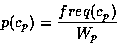
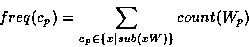
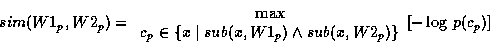
The specific senses of W1p, W2p under which semantic similarity holds is determined with respect to the subsumption relation linking cp with W1p, W2p . Suppose for example that in calculating the semantic similarity of the two verbs fire, dismiss using the WordNet lexical database we find that the most informative subsuming concept is represented by the synonym set containing the word sense remove_v_2. We will then know that the senses for fire, dismiss under which the similarity holds are fire_v_4 and dismiss_v_4 as these are the only instances of the verbs fire and dismiss subsumed by remove_v_2 in the WordNet hierarchy.
Such an approach, combining a taxonomic structure with empirical probability estimates, provides a way of tailoring a static knowledge structure such as a semantic taxonomy onto specific texts.
In the work reported by [Bro91], each target word Ti is characterised by the words that immediately follow it in a text. More formally, the context of Ti is denoted by a vector C(Ti) defined as follows:
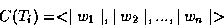
In related work, words are not clustered in terms of frequency counts for the word immediately following T, but rather by looking at a text window of about one thousand words surrounding T. The problem with this and similar approaches is that they are considerably greedy without being completely reliable. Since it is hard to know a priori which word to pull out of the context of a target word to best characterise its sense contextually, blind algorithms are deployed that take into account the largest possible environment around T. Still, this approach can be proved to fail to take into account all relevant contextual evidence, since relevant words are shown by [Gal92a] to be possibly found as far away as 1000 words from the target word.
An attempt to characterise word usage on a sounder linguistic basis is reported by [Per92] who work on examples of verb-object relation found in a corpus. The vector associated with a target noun nk to characterise its sense contains the (conditional) distribution of verbs for which it serves as direct object in a corpus. The metric used in this study is relative entropy and the representation of the resulting classes is a tree structure of groups.
A further development of this approach is reported in Grefenstette, who characterises the target word in terms of more than one syntactic relation, including subject, object, indirect-object and modifier. For each target noun Ti the resulting representation is a vector C(Ti) of counts for every other word wj and each of the four possible syntactic relations between Ti and wj. [Sek92] apply a simplified version of the same technique to triples with the following structure:
[Fed96,Fed97] make the same assumption as [Sek92] but apply it to examples of verb-object and verb-subject relations. Distributionally-based semantic similarity is computed on both terms of these relations. Thus, verbs are taken to be semantically similar if they share some words serving as direct object or subject. By the same token, nouns are semantically similar if they serve as subject and/or object for a shared subset of verbs. A notion of semantic proportional analogy is developed resting on both types of word clustering: this notion gives, for a given target word in context, its closest semantic analogue(s). Unlike all approaches considered so far, whereby word clusters are defined once and for all by averaging out counts for words in context, semantic proportional analogy varies depending on the context. Thus, the same word T selects a different closest analogue depending whether T is considered in the company of the object Oi or the object Oj. This technique is reported to be robust enough to be able to overcome both noisy and sparse data problems.
As we saw above, two words can be considered to be semantically related if they typically co-occur within the same context. In the section on distributionally-based semantic similarity, we showed that word co-occurrence patterns are instrumental for identifying clusterings of semantically similar words. In this section, word co-occurrence patterns will be considered as such together with their use for the resolution of a number of NLP problems.
In the literature, various scholars have suggested that ambiguity resolution (e.g. prepositional phrase attachment) is strongly influenced by the lexical content of specific words ([For82,Mar80] to mention only a few). Yet, for this assumption to be assessed in practice, the necessary information about lexical associations was to be acquired. Recently, an upsurge of interest in corpus-based studies led a number of scholars to collect lexical co-occurrence data from large textual corpora; among them - to mention only a few - [Chu89,Cal90,Hin93,Sma93,Rib94,Tsu92]. Collected patterns were successfully used for different disambiguation purposes. For instance, [Hin93] show how structural ambiguities such as prepositional phrase attachment can be resolved on the basis of the relative strength of association of words, estimated on the basis of distribution in an automatically parsed corpus. Similar results are reported in [Tsu92].
All types of word clustering reviewed so far have been widely studied from the theoretical point of view in the field of lexical semantics where it is commonly assumed that the semantic properties of a lexical item are fully reflected in the relations it contracts in actual and potential linguistic contexts, namely on the syntagmatic and paradigmatic axes.
Sense relations are of two fundamental types: paradigmatic and syntagmatic. Paradigmatic relations such as synonymy, hyperonymy/hyponymy, antonymy or meronymy occupy focal positions in discussions of lexical semantics (see, for instance, [Cru86]). They reflect the way reality is categorised, subcategorised and graded along specific dimensions of lexical variation. By contrast, syntagmatic aspects of lexical meaning form a less prominent topic of lexical semantics which in the literature is generally referred to as co-occurrence restrictions. Two different kinds of co-occurrence restrictions are commonly distinguished: selection restrictions, which are defined in very general terms as ``any of various semantic constraints reflected in the ability of lexical items to combine in syntactic structures'' [Tra94]; collocational restrictions, which are ``unusually idiosyncratic or language- specific'' (ibidem) restrictions.
Nowadays, a new trend in the lexical semantics literature is emerging which questions the watertight classification of meanings presupposed by traditional approaches to lexical semantics. Under this view, word senses are defined in terms of clear, typical, central cases (called ``prototypes'') rather than in terms of their boundaries which very often appear as unclear and undefinable (see [Cru94]).
The various word clustering techniques described so far have a large number of potentially important applications, including: