Dependency Grammar resorts to the old idea that syntax is almost entirely a matter of the combination capabilities and completion requirements of words. Since the influential work of Tesnière (1959), the model for describing these phenomena is akin to the formation of molecules from atoms in chemistry. Like atoms, words have valency; they are apt to combine with a certain number and kind of other words forming larger chunks of linguistic material. Valency descriptions of words do not only correspond with the subcategorisation component in other frameworks but are the sole device of generating syntactic structures in the lexicalist versions of dependency grammar.
Dependency grammars, like phrase structure grammars, use trees (directed acyclic graphs) in order to depict the structure of a given phrase or sentence. While a phrase structure grammar associates the nodes in the tree with larger or smaller constituents and uses the arcs to represent the relationship between a part and the whole, all nodes in a dependency tree represent elementary constituents and the arcs denote the direct syntagmatic relationships between such elements.
Dependency grammar assumes that there is usually an asymmetry between immediate constituents of a phrase: one constituent is the governor or head, the other ones are the dependents. For example, one constituent may be a predicate, the other constituents are arguments; one constituent may be a modifier, the other one is modified. The governor gives rise to the whole construction and determines it. Dependents adjust to the demands imposed on the construction by the governor. The difference between heads and dependents is reflected by the hierarchy of nodes in the dependency tree.
Since each node represents an elementary segment (a terminal category), the nodes in a dependency tree are typically labeled by lexemes.
The sentence in (34) may be represented by the bracketed expression of (35), which is equivalent to a dependency tree:
(34) | The big dog chases the cat. |
|
(35) |
|
It is no problem to add part-of-speech categories to the node labels, as in (36):
|
(36) |
|
The dependency structure is especially suitable for functional categorisations, as in (37):
|
(37) |
|
Both functional and morphosyntactic categories can be merged in the same tree, as in (38). Word order, which is not inherent in the tree structure, can be depicted by additional labeling, e.g. by the symbol `<' for ``left of the head'' and `>' for ``right of the head'':
|
(38) |
|
A common misconception of the dependency relation must be mentioned
here. Dependency is not a word-to-word relationship but a
word-to-complement relationship. A complement can consist
of many words. For example, the noun phrase the big dog is the
subject complement of the verb chase in the above sentence
rather than just the word dog; the phrase the cat is the
object rather than just the word cat. Internally, any phrase is
again structured according to word-to-complement principles and is
represented as such. Therefore, all nodes in a dependency tree
eventually correspond to terminal elements. Nevertheless, a dependency
relationship only exists between a word at a dominating node and the
whole phrases represented by the dependent subtree. As a consequence,
the part-of-speech categories associated with the nodes are not really
terminal. Similar to 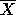 theory, the categories of the lexical head
in a phrase characterise the whole phrase.
theory, the categories of the lexical head
in a phrase characterise the whole phrase.
Quite a few Dependency Grammars have recently been developed. See Fraser (1994) for a survey. In the following, we describe the role of subcategorisation in Dependency Unification Grammar (DUG). DUG has been implemented at the Institute for Computational Linguistics of the University of Heidelberg as a framework for parsing natural languages, see Hellwig (1983). DUGs for German, French and English have been drawn up for the ESPRIT and LRE projects ``Translator's Work Bench'' (TWB) and ``Selecting Information from Text'' (SIFT).
Sentence (39)
|
(39) | Arthur attends the EAGLES meeting. |
is turned into the representation of (40) by the parser:
Without going into details, this much should be noted: (40) is a dependency tree with six nodes, one node for each elementary constituent from (39), including the full stop. Each node carries three types of information: a syntactic function (ILLOC, PROPOS, SUBJECT, DIR_OBJ1, DETER, ATTR_NOM), a lexeme (statement', attend, Arthur, meeting, definit', EAGLES) and a set of morphosyntactic features introduced by a part of speech category (sign, verb, noun, determiner).
What are the lexical prerequisites for the parser to construct such an output? As opposed to common generative grammars, a DUG does not consist of a set of production rules from which a formal representation is created in a separate step. DUG directly describes syntactic structures as fragments of the target representation. Basically three data sets are needed: a morphosyntactic lexicon, a set of valency templates and a valency lexicon.
The morphosyntactic lexicon relates each elementary string of the language (i.e. each word form) to a lexeme and a complex morphosyntactic category.
A valency template directly mirrors a fragment of a dependency tree. As such, it describes a specific syntagmatic relationship, e.g. the relationship between a verb and a subject or a verb and a direct object, between a noun and a determiner or two nouns in a compound, etc. Templates typically contain a dominating term which stands for the head node in the syntagmatic relation, and a dependent term functioning as a variable for a dependent node. The latter is called a slot. Templates describe the combination capability of words by means of slots which are to be filled by appropriate material from the context. The set of templates in a DUG has a similar function as the set of rules in a generative grammar.
The following templates in (41) have been used in the tree in example (40):
Note that each template characterises the morphosyntactic form of the head, the syntactic function of the dependent and the morphosyntactic form of the dependent. If need be, lexical selections can also be specified in a slot.
The valency lexicon consists of references. A reference assigns a template or a set of templates to a lexical item, thus describing the combination capability of the item. There are three kinds of references according to the possible functions of templates: complements, adjuncts and conjuncts.
DUG makes a theoretical and technical distinction between complements and adjuncts. Theoretically, complements are dependents of a lexical item that are required by the word's inherent combinatorial semantics. Adjuncts, on the contrary, augment the dependency structure by their own virtue. While a term is incomplete until it has found its complements, adjuncts can be added to the set of dependents of a term in a relatively arbitrary fashion.
As a rule, complements are specified in the lexicon under the lemma of the governing term (i.e. in a top down fashion). Adjunct templates are specified in the lexical entry of the adjunct word, defining the potential of attachment of the lexical item as a dependent (i.e. in a bottom up fashion).
A conjunct is a phrase, usually introduced by a coordinator like and and or, which is attached to the rest of a sentence resulting in the coordination of some of its parts. The references of (42) link up the lexical items in sentence (39) with the templates of (41). (The full stop has the lexeme statement' and the determiner the is represented by the lexeme definite'.)
These references are in fact the means how subcategorisation is implemented in a DUG. Remember each template which is mentioned in a reference is a combination of a syntactic function and a morphosyntactic realisation. There can be more than one template with the same name in order to characterise syntagmatic alternations of realisations. For example, among the subject templates are the (43) and (44) that describe the subjects in questions:
|
(43) | |
| (*:+subject:verb auxiliary[+] form[finite,subjunctive] | |
| s_type[question] s_position[6] | |
| (> SUBJECT:=:noun person[C] determined[+] s_position[7])); |
|
(44) | |
| (*:+subject:verb form[finite,subjunctive] s_type[question, | |
| relative] s_position[6] | |
| (< SUBJECT:=:pronoun pro_form[interrogative, relative,C] person[C] gender[C] case[subjective] n_position[2])); |
The first subject template (43) describes the subject of Did Arthur attend the meeting and the second template (44) accounts for Who did attend the meeting?. Both templates are already covered by the reference for attend in (42).
Alternations of templates can also be stated as an explicit disjunction in a reference, as in (45):
|
(45) | |
| (:COMPLEMENTS (:surprise) (& (, (:+subject_that) | |
| (:+subject_inf_to) (:+subject_ing)) (:+dir_obj1))); |
This description covers That he came surprises me, To see him here surprises me, Seeing him here surprises me.
DUG describes the argument structure as a level of syntactic description. Usually, there is no ranking of participant roles. On the contrary, the subject is considered to be an argument of the verb as anything else (e.g. objects). Control and extraposition structures are handled by assignment of specific templates to the verbs that give rise to these structures. There is a mechanism of expansion rules (not covered in this survey) which creates additional templates on the basis of the ones in the lexicon, e.g. the template for the agent slot in the passive is created from the lexical coding of a direct transitive object. The same is true for the slot of it as a correlate with a subject or object clause.