In this section, the different approaches to verb subcategorisation taken by the abovementioned lexicons are briefly described. We will mainly focus on the following general aspects:
The treatment of subcategorisation for the Acquilex lexicon (Sanfilippo, 1993b) was developed using a Unification Categorial Grammar model (hereafter UCG) combined with a sign-based approach to lexical representation. While the description of verb types in Acquilex was meant to be compatible with several theoretical approaches, reference to a specific grammar framework was deemed to be necessary in order to test the fragment built (i.e. parse representative sentences). UCG was chosen because it provided a radically lexical theory of grammar; this ensured that lexical entries would contain as much information as can be appropriately captured in the lexicon. Consequently, modification for a different framework would be a process of (automatically) removing or transforming information, but not (manually) adding more. Word senses are criterial for identification/distinction of an independent lexical entry.
ILCLEX is intended to provide a theory-independent lexical representation. Three hierarchically ordered information levels were identified: pattern rules, patterns and subcategorisation frames. At the bottom level, subcategorisaton information corresponds to an explicit encoding of the various grammatical contexts the verb can occur in: the syntactic realisation of arguments is taken to be criterial for identification of a single subcategorisation frame. Patterns generalise over different sucategorisation frames abstracting away from the syntactic realisation of arguments. Pattern rules, at the top level, link different but related patterns of the same verb to one another. Note that the same pattern as well as the same subcategorisation frame can refer to different verb senses.
The Comlex subcategorisation model is based on the set of subcategorisation classes developed for Sager's Linguistic String Project Dictionary, with influences from the Brandeis Verb Lexicon. The dictionary consists of a list of detailed definitions of subcategorisation features and a set of word definitions which reference those features. The verb frame structure is articulated into two levels, the constituent structure (a list of surface structure constituents such as NP, PP, ADJP etc., immediately followed by a number used to coindex the constituent and grammatical structures), and the grammatical structure (a list of grammatical relations each followed by an index referring to an element from the constituent structure). The identity of a lexical entry is defined in syntactic terms only, regardless of sense variation.
The stratificational nature of the Eurotra unification-based grammar implies four different levels of linguistic description: the morphological level, the configurational or constituent level, the relational syntactic level and the interface or semantic level. Each level has its own grammar and its own lexicon. All of them, except the first one, could be considered relevant to the issue of verbal subcategorisation. In what follows, the Eurotra lexicon will be taken as a whole, and an indication of the linguistic level to which a specific aspect pertains is provided only when and if relevant. Note that at the interface structure level, different senses of the same verb give rise to different lexical entries. This does not hold at lower levels where syntactic criteria, either constituency-based or relational, are relevant to entry identification.
In the Genelex model, which is aimed at being theory-welcoming, an
entry is a complex and structured object defined in terms of: a lexical
unit, its syntactic behaviour and its complementation frame
(subcategorisation frame in our terminology). For each complement within a
complementation frame, its position and syntactic realisation is specified
together with all sorts of restrictions when needed. Some notions are
parameterisable: for instance, a complement can be defined either in purely
syntactic terms (distribution paradigm, function) or in semantic ones
(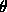 roles, semantic classes). Complementation patterns are not defined a priori,
but can be tailored by the lexicographer to meet specific
needs/applications. Both fine and coarse grained information can thus be
couched in the model. At the moment, the Genelex dictionary contains, for
each word, its complementation pattern specified for number of complements,
their optionality (when relevant), their syntactic realisation, and lexical
or morphosyntactic restrictions.
roles, semantic classes). Complementation patterns are not defined a priori,
but can be tailored by the lexicographer to meet specific
needs/applications. Both fine and coarse grained information can thus be
couched in the model. At the moment, the Genelex dictionary contains, for
each word, its complementation pattern specified for number of complements,
their optionality (when relevant), their syntactic realisation, and lexical
or morphosyntactic restrictions.
The PLNLP lexicon is a broad coverage lexicon, basically consisting of a list of word stems and fairly simple feature information associated with them, i.e. part of speech, morphological and subcategorisation features. It adopts a compact lexical representation strategy, since all different subcategorisation features for the same verb are collapsed within the same lexical entry regardless of sense distinctions.
In addition to part of speech information LDOCE specifies, for each entry, a subcategorisation description in terms of types and numbers of complements.When the same verb can take different types of complements without significant change in meaning, these are encoded as alternative subcategorisations (alternations) within the same entry. In the late 80s, LDOCE represented the most comprehensive description of grammatical properties of words to be found in any published dictionary available in machine readable form. This is why it is certainly worth considering in this overview of practical NLP lexicons mainly as a source of computational lexicons rather than a computational lexicon in its own right.